Note
Go to the end to download the full example code.
Fitting NuSTAR Spectra: General Tutorial#
A real example of fitting a NuSTAR spectrum.
import warnings
import matplotlib.pyplot as plt
import numpy as np
from numpy.exceptions import VisibleDeprecationWarning
from parfive import Downloader
from sunkit_spex.legacy.fitting.fitter import Fitter, load
warnings.filterwarnings("ignore", category=RuntimeWarning)
try:
warnings.filterwarnings("ignore", category=VisibleDeprecationWarning)
except AttributeError:
warnings.filterwarnings("ignore", category=np.exceptions.VisibleDeprecationWarning)
Set up some plotting numbers
spec_single_plot_size = (8, 10)
spec_plot_size = (25, 10)
spec_font_size = 18
default_font_size = 10
x_limits, y_limits = [1.6, 8.5], [1e-1, 1e3]
Download the example data
dl = Downloader()
base_url = "https://sky.dias.ie/public.php/dav/files/BHW6y6aXiGGosM6/nustar/m3_time2628/"
file_names = [
"nu80414202001A06_chu23_S_cl_grade0_sr.pha",
"nu80414202001A06_chu23_S_cl_grade0_sr.arf",
"nu80414202001A06_chu23_S_cl_grade0_sr.rmf",
]
for fname in file_names:
dl.enqueue_file(base_url + fname, path="../../nustar/m3_time2628/")
files = dl.download()
Files Downloaded: 0%| | 0/3 [00:00<?, ?file/s]
nu80414202001A06_chu23_S_cl_grade0_sr.rmf: 0%| | 0.00/34.0M [00:00<?, ?B/s]
nu80414202001A06_chu23_S_cl_grade0_sr.arf: 0%| | 0.00/63.4k [00:00<?, ?B/s]
nu80414202001A06_chu23_S_cl_grade0_sr.pha: 0%| | 0.00/132k [00:00<?, ?B/s]
nu80414202001A06_chu23_S_cl_grade0_sr.rmf: 0%| | 1.02k/34.0M [00:00<1:28:19, 6.41kB/s]
nu80414202001A06_chu23_S_cl_grade0_sr.arf: 2%|▏ | 1.02k/63.4k [00:00<00:09, 6.72kB/s]
nu80414202001A06_chu23_S_cl_grade0_sr.pha: 1%| | 1.02k/132k [00:00<00:19, 6.66kB/s]
nu80414202001A06_chu23_S_cl_grade0_sr.rmf: 0%| | 42.0k/34.0M [00:00<04:09, 136kB/s]
nu80414202001A06_chu23_S_cl_grade0_sr.arf: 66%|██████▋ | 42.0k/63.4k [00:00<00:00, 136kB/s]
Files Downloaded: 33%|███▎ | 1/3 [00:00<00:01, 1.35file/s]
nu80414202001A06_chu23_S_cl_grade0_sr.pha: 32%|███▏ | 42.0k/132k [00:00<00:00, 136kB/s]
nu80414202001A06_chu23_S_cl_grade0_sr.pha: 100%|█████████▉| 132k/132k [00:00<00:00, 379kB/s]
Files Downloaded: 67%|██████▋ | 2/3 [00:00<00:00, 2.68file/s]
nu80414202001A06_chu23_S_cl_grade0_sr.rmf: 1%| | 214k/34.0M [00:00<01:08, 490kB/s]
nu80414202001A06_chu23_S_cl_grade0_sr.rmf: 2%|▏ | 554k/34.0M [00:00<00:26, 1.24MB/s]
nu80414202001A06_chu23_S_cl_grade0_sr.rmf: 4%|▎ | 1.23M/34.0M [00:00<00:11, 2.74MB/s]
nu80414202001A06_chu23_S_cl_grade0_sr.rmf: 7%|▋ | 2.30M/34.0M [00:00<00:06, 4.94MB/s]
nu80414202001A06_chu23_S_cl_grade0_sr.rmf: 14%|█▍ | 4.83M/34.0M [00:00<00:02, 10.7MB/s]
nu80414202001A06_chu23_S_cl_grade0_sr.rmf: 23%|██▎ | 7.77M/34.0M [00:01<00:01, 16.1MB/s]
nu80414202001A06_chu23_S_cl_grade0_sr.rmf: 33%|███▎ | 11.1M/34.0M [00:01<00:01, 19.8MB/s]
nu80414202001A06_chu23_S_cl_grade0_sr.rmf: 44%|████▎ | 14.8M/34.0M [00:01<00:00, 22.9MB/s]
nu80414202001A06_chu23_S_cl_grade0_sr.rmf: 55%|█████▍ | 18.6M/34.0M [00:01<00:00, 25.0MB/s]
nu80414202001A06_chu23_S_cl_grade0_sr.rmf: 66%|██████▌ | 22.3M/34.0M [00:01<00:00, 26.2MB/s]
nu80414202001A06_chu23_S_cl_grade0_sr.rmf: 77%|███████▋ | 26.1M/34.0M [00:01<00:00, 27.3MB/s]
nu80414202001A06_chu23_S_cl_grade0_sr.rmf: 88%|████████▊ | 29.9M/34.0M [00:01<00:00, 28.3MB/s]
nu80414202001A06_chu23_S_cl_grade0_sr.rmf: 99%|█████████▉| 33.6M/34.0M [00:01<00:00, 29.4MB/s]
Files Downloaded: 100%|██████████| 3/3 [00:02<00:00, 1.16file/s]
Files Downloaded: 100%|██████████| 3/3 [00:02<00:00, 1.31file/s]
Load in one spectrum and fit it with one model
All the data can be accessed via spec.loaded_spec_data
Next you can define a model, here we go for a single isothermal model
spec.model = "f_vth"
And all data can be accessed via spec.params.
print(spec.params)
Status Value Bounds Error
T1_spectrum1 free 1.0 (0.0, None) (0.0, 0.0)
EM1_spectrum1 free 1.0 (0.0, None) (0.0, 0.0)
Set your count energy fitting range. Here we choose 2.5–8.1 keV
spec.energy_fitting_range = [2.5, 8.1]
To set the initial value and boundary of your parameters we can do the following:
spec.params["T1_spectrum1"] = {"Value": 4, "Bounds": (2.5, 8)} # units MK
spec.params["EM1_spectrum1"] = {"Value": 0.3, "Bounds": (1e-1, 8e-1)} # units 1e46 cm^-3
Setting spec.params["param_spec"] = string will set the Status, spec.params["param_spec"] = int or float will set the Value, spec.params["param_spec"] = tuple will set the Bounds.
I.e., spec.params["T1_spectrum1"] = {"Value":3.05, "Bounds":(2.5, 6)} is the same as doing spec.params["T1_spectrum1"]=3.05 and then spec.params["T1_spectrum1"]=(2.5, 6).
print(spec.params)
Status Value Bounds Error
T1_spectrum1 free 4.0 (2.5, 8) (0.0, 0.0)
EM1_spectrum1 free 0.3 (0.1, 0.8) (0.0, 0.0)
Once data has been loaded and a model set then the data can be fitted.
Any kwargs passed to fit will be sent to Scipy’s minimize. E.g., tol=1e-6 for setting a tolerance for the fit.
minimised_params = spec.fit()
The spec.params will be updated with the best fit values and errors (if obtained) too.
print(spec.params)
Status ... Error
T1_spectrum1 free ... (0.06054753323903626, 0.06054753323903626)
EM1_spectrum1 free ... (0.0222790370742351, 0.0222790370742351)
[2 rows x 4 columns]
Plot the result with the plot method:
plt.rcParams["font.size"] = spec_font_size
plt.figure(figsize=spec_single_plot_size)
# the only line needed to plot the result
axes, res_axes = spec.plot()
for a in axes:
a.set_xlim(x_limits)
a.set_ylim(y_limits)
plt.show()
plt.rcParams["font.size"] = default_font_size
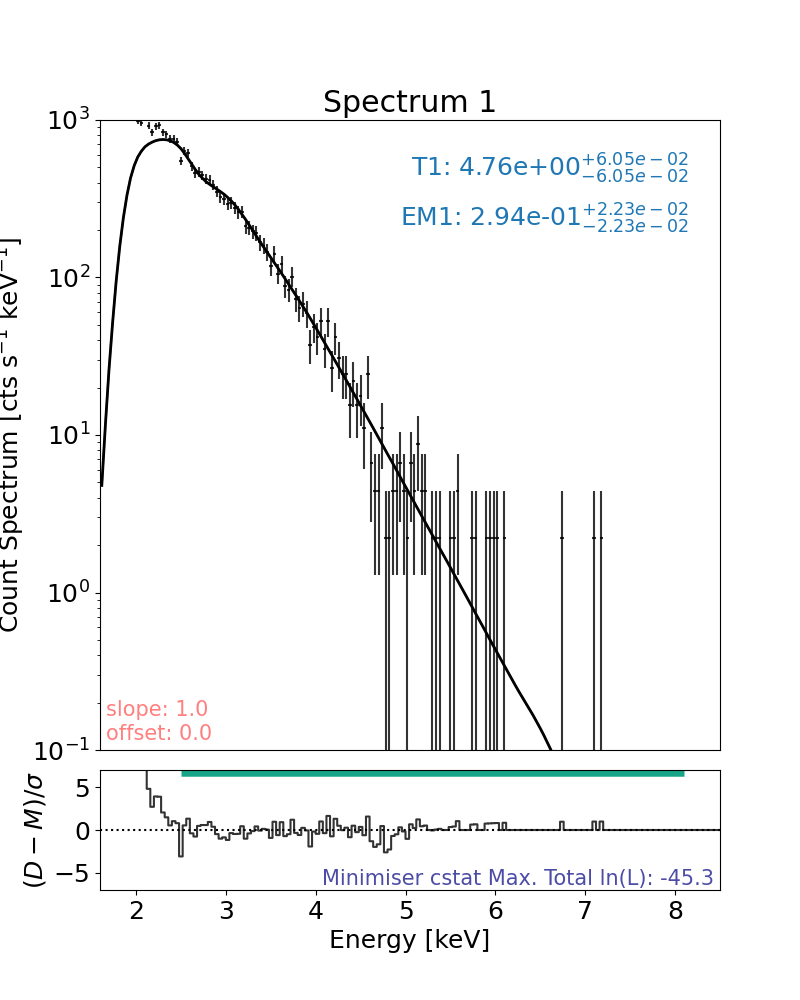
The data loader class
The data loader class (LoadSpec in data_loader.py) makes use of instrument specific loaders. Each instrument loader’s job is to essentially create the following dictionary for each loaded spectrum, found with the attribute _loaded_spec_data in the instrument class which makes up the loader class’s data.loaded_spec_data dictionary. E.g., with NuSTAR:
nust_loader._loaded_spec_data = {"photon_channel_bins":channel_bins,
"photon_channel_mids":np.mean(channel_bins, axis=1),
"photon_channel_binning":channel_binning,
"count_channel_bins":channel_bins,
"count_channel_mids":np.mean(channel_bins, axis=1),
"count_channel_binning":channel_binning,
"counts":counts,
"count_error":count_error,
"count_rate":count_rate,
"count_rate_error":count_rate_error,
"effective_exposure":eff_exp,
"srm":srm,
"extras":{"pha.file":f_pha,
"arf.file":f_arf,
"arf.e_lo":e_lo_arf,
"arf.e_hi":e_hi_arf,
"arf.effective_area":eff_area,
"rmf.file":f_rmf,
"rmf.e_lo":e_lo_rmf,
"rmf.e_hi":e_hi_rmf,
"rmf.ngrp":ngrp,
"rmf.fchan":fchan,
"rmf.nchan":nchan,
"rmf.matrix":matrix,
"rmf.redistribution_matrix":redist_m}
}
such that, spec.data.loaded_spec_data == {"spectrum1":nust_loader._loaded_spec_data, ...}
Multiple ways to set the fitting range
Fit the energy range while missing bins:
This only will fit the counts from 2.5–4 keV and 4.5–8.1 keV and is applied to all spectra loaded
spec.energy_fitting_range = [[2.5, 4], [4.5, 8.1]]
Rebin the data (not just for plotting)
Rebin all the count data being fitted to have a minimum of 4 counts in a bin, any counts left over will not be included and the user will be told.
spec.rebin = 4
# or equivalently
spec.rebin = {"all": 4}
# or equivalently if just one spectrum is loaded
spec.rebin = {"spectrum1": 4}
Undo the rebinning of the data
To revert back to native binning for all spectra:
# For one spectrum
spec.undo_rebin = "spectrum1"
# or (indicate the spectrum with just its number)
spec.undo_rebin = 1
# or explicitly state the rebinning should be reverted to all spectra
spec.undo_rebin = "all"
Save what you have
To save the fitting class to a file called ‘test.pickle’.
spec.save("./test.pickle")
Load it back in and continue analysis:
To load a saved session back in
new_spec = load("./test.pickle")
print(new_spec.params)
Status ... Error
T1_spectrum1 free ... (0.06054753323903626, 0.06054753323903626)
EM1_spectrum1 free ... (0.0222790370742351, 0.0222790370742351)
[2 rows x 4 columns]
run fit again since the energy range being fitted over has been changed after the last fit
new_spec.fit(tol=1e-6) # Scipy minimize tolerance of 1e-6
[4.717251178489729, 0.30766783569520506]
Plot the data and rebin it (just for plotting), fit was in natural binning
rebin=10 means the count bins were combined so that all bins had at least 10 counts in them or were ignored
plt.rcParams["font.size"] = spec_font_size
plt.figure(figsize=spec_single_plot_size)
axes, res_axes = new_spec.plot(rebin=10)
for a in axes:
a.set_xlim(x_limits)
a.set_ylim(y_limits)
plt.show()
plt.rcParams["font.size"] = default_font_size
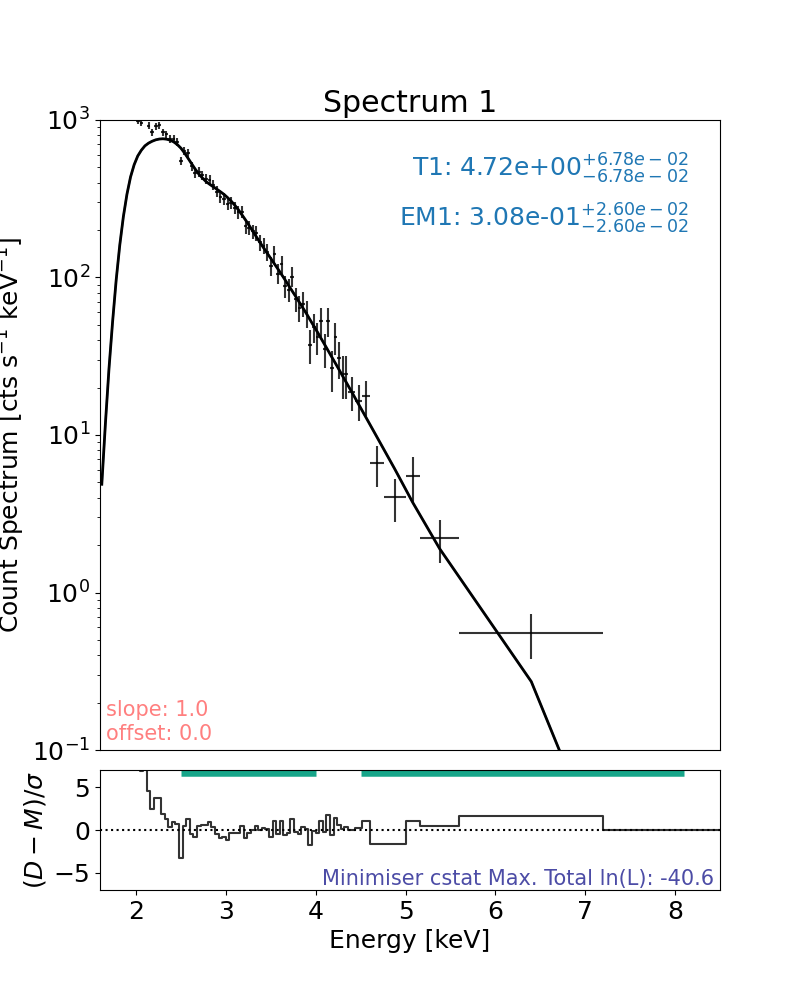
Easily run an MCMC on your data with your model
mcmc_result = spec.run_mcmc(steps_per_walker=100)
0%| | 0/100 [00:00<?, ?it/s]
4%|▍ | 4/100 [00:00<00:02, 34.39it/s]
8%|▊ | 8/100 [00:00<00:03, 30.42it/s]
12%|█▏ | 12/100 [00:00<00:03, 29.26it/s]
15%|█▌ | 15/100 [00:00<00:02, 28.73it/s]
18%|█▊ | 18/100 [00:00<00:02, 28.56it/s]
21%|██ | 21/100 [00:00<00:02, 28.47it/s]
24%|██▍ | 24/100 [00:00<00:02, 28.37it/s]
27%|██▋ | 27/100 [00:00<00:02, 28.30it/s]
30%|███ | 30/100 [00:01<00:02, 28.26it/s]
33%|███▎ | 33/100 [00:01<00:02, 28.15it/s]
36%|███▌ | 36/100 [00:01<00:02, 28.08it/s]
39%|███▉ | 39/100 [00:01<00:02, 27.99it/s]
42%|████▏ | 42/100 [00:01<00:02, 28.02it/s]
45%|████▌ | 45/100 [00:01<00:01, 28.03it/s]
48%|████▊ | 48/100 [00:01<00:01, 28.02it/s]
51%|█████ | 51/100 [00:01<00:01, 28.08it/s]
54%|█████▍ | 54/100 [00:01<00:01, 27.99it/s]
57%|█████▋ | 57/100 [00:02<00:01, 28.00it/s]
60%|██████ | 60/100 [00:02<00:01, 27.76it/s]
63%|██████▎ | 63/100 [00:02<00:01, 27.65it/s]
66%|██████▌ | 66/100 [00:02<00:01, 27.79it/s]
69%|██████▉ | 69/100 [00:02<00:01, 27.90it/s]
72%|███████▏ | 72/100 [00:02<00:01, 27.98it/s]
75%|███████▌ | 75/100 [00:02<00:00, 28.03it/s]
78%|███████▊ | 78/100 [00:02<00:00, 28.11it/s]
81%|████████ | 81/100 [00:02<00:00, 28.06it/s]
84%|████████▍ | 84/100 [00:02<00:00, 28.13it/s]
87%|████████▋ | 87/100 [00:03<00:00, 28.16it/s]
90%|█████████ | 90/100 [00:03<00:00, 27.67it/s]
93%|█████████▎| 93/100 [00:03<00:00, 27.33it/s]
96%|█████████▌| 96/100 [00:03<00:00, 27.56it/s]
99%|█████████▉| 99/100 [00:03<00:00, 27.60it/s]
100%|██████████| 100/100 [00:03<00:00, 28.13it/s]
To add more MCMC runs, avoid overwriting by setting append_runs=True.
mcmc_result = spec.run_mcmc(steps_per_walker=50, append_runs=True)
0%| | 0/50 [00:00<?, ?it/s]
6%|▌ | 3/50 [00:00<00:01, 26.30it/s]
12%|█▏ | 6/50 [00:00<00:01, 26.86it/s]
18%|█▊ | 9/50 [00:00<00:01, 27.06it/s]
24%|██▍ | 12/50 [00:00<00:01, 27.43it/s]
30%|███ | 15/50 [00:00<00:01, 27.23it/s]
36%|███▌ | 18/50 [00:00<00:01, 27.23it/s]
42%|████▏ | 21/50 [00:00<00:01, 27.53it/s]
48%|████▊ | 24/50 [00:00<00:00, 27.71it/s]
54%|█████▍ | 27/50 [00:00<00:00, 27.83it/s]
60%|██████ | 30/50 [00:01<00:00, 27.94it/s]
66%|██████▌ | 33/50 [00:01<00:00, 27.98it/s]
72%|███████▏ | 36/50 [00:01<00:00, 27.96it/s]
78%|███████▊ | 39/50 [00:01<00:00, 28.02it/s]
84%|████████▍ | 42/50 [00:01<00:00, 28.00it/s]
90%|█████████ | 45/50 [00:01<00:00, 27.55it/s]
96%|█████████▌| 48/50 [00:01<00:00, 27.17it/s]
100%|██████████| 50/50 [00:01<00:00, 27.54it/s]
MCMC runs are easily burned and are always burned from the original sampling. E.g., burning 50 samples twice still only discards 50 samples, to discard 100 the user needs to just discard 100.
spec.burn_mcmc = 30
Plot the log-probability chains
plt.figure()
spec.plot_log_prob_chain()
plt.show()
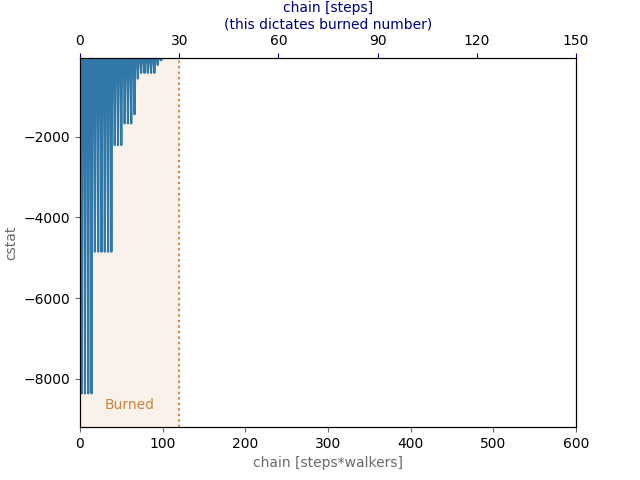
Plot the corner plot from the MCMC run (just send the data to corner.py)
corner_plot = spec.corner_mcmc()
plt.rcParams["font.size"] = spec_font_size
plt.figure(figsize=spec_single_plot_size)
axes, res_axes = spec.plot()
for a in axes:
a.set_xlim(x_limits)
a.set_ylim(y_limits)
plt.show()
plt.rcParams["font.size"] = default_font_size
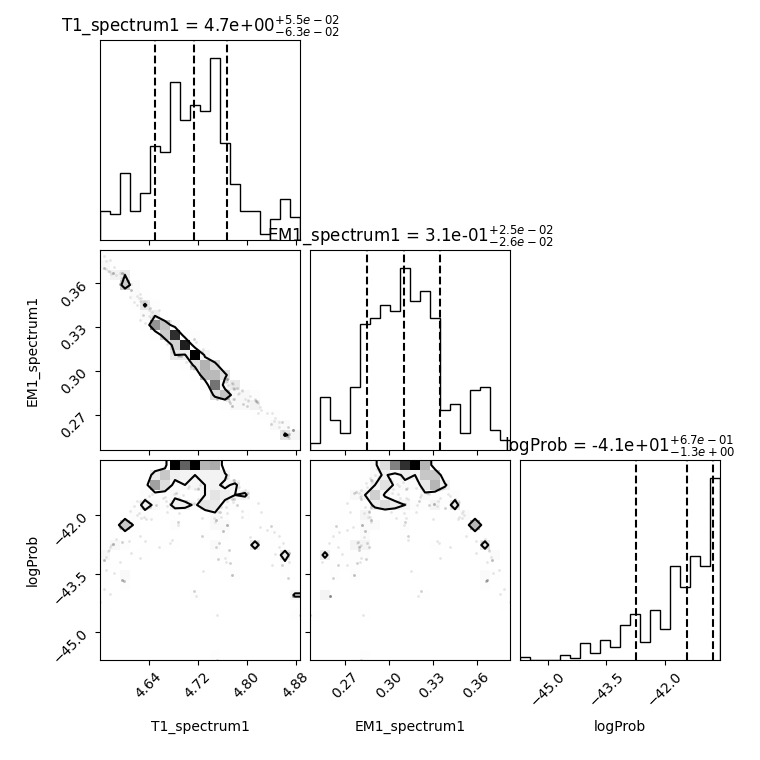
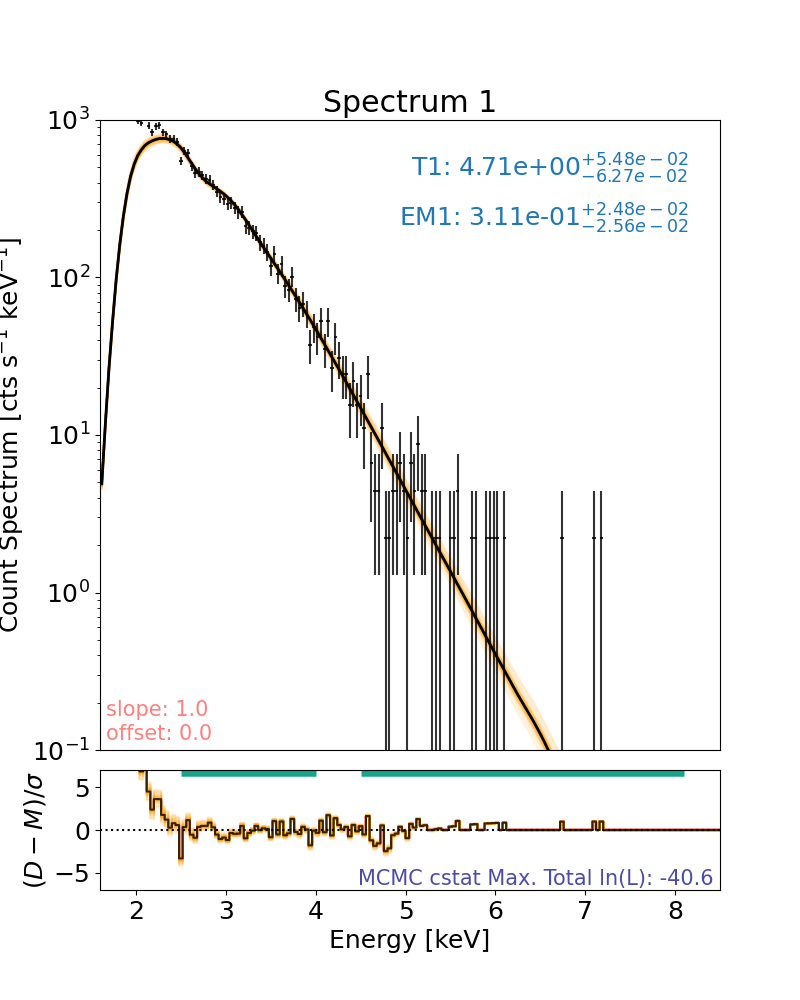
Note that the log-likelihood displayed on the spectral plots show the the maximum log-likelihood found in the MCMC run, not the log-likelihood of the maximum a posteriori (MAP) fit plotted.
The log-likelihoods of the median and confidence ranges can be found on the corner plot at the minute and the parameter values that produce these can be found with the mcmc_table attribute.
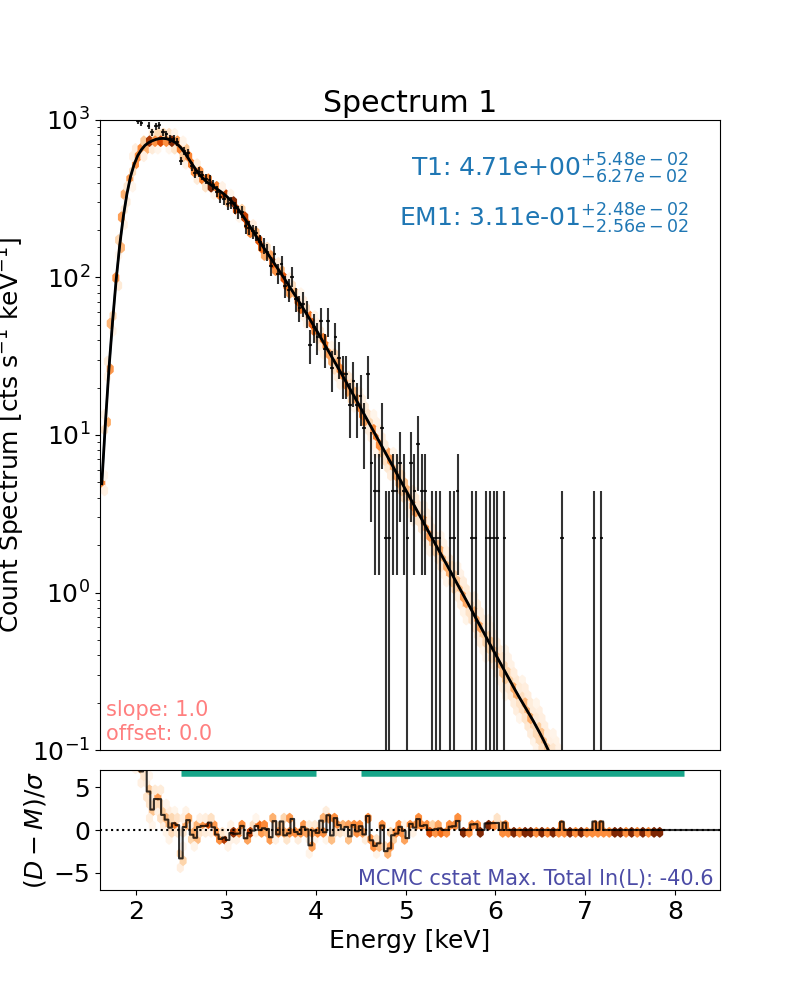
An alternative to plotting a number of random MCMC samples as faded lines, the user can plot a colour map showing where all run models (that are not burned) accumulate counts. This will obviously take longer.
plt.rcParams["font.size"] = spec_font_size
plt.figure(figsize=spec_single_plot_size)
axes, res_axes = spec.plot(hex_grid=True)
for a in axes:
a.set_xlim(x_limits)
a.set_ylim(y_limits)
plt.show()
plt.rcParams["font.size"] = default_font_size
Total running time of the script: (0 minutes 34.390 seconds)